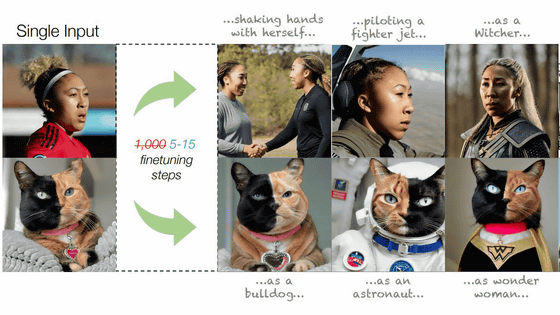
画像生成AI「Stable Diffusion」がどのような仕組みでテキストから画像を生成するのかを詳しく図解

高精度な画像を生成できることで話題となっている「Stable Diffusion」が、どのように入力されたテキスト(プロンプト)からイラストを生成しているのかについて、機械学習関連のトピックについての解説動画などを投稿しているジェイ・アラマー氏が解説しています。
The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
https://jalammar.github.io/illustrated-stable-diffusion/
アラマー氏は、テキストから印象的な画像を生成するAIの登場が、人間がアートを作成する方法が変わることを示していると主張。Stable Diffusionのリリースにより、比較的安いリソースで使用で誰もが高性能なモデルを使用可能になったと述べ、図解を利用してStable Diffusionが画像を生成する仕組みについて解説しました。
◆Stable Diffusionのコンポーネント
ユーザーから見たStable Diffusionを単純化すると以下の通り。「paradise cosmic beach(楽園の広いビーチ)」というテキストを入力すると、それらしい画像が生成されます。

また、上記で生成した画像に「Pirate ship(海賊船)」というテキストを合わせ、さらに画像を変化させることも可能となっています。

Stable Diffusionは複数のコンポーネントとモデルで構成されるシステムであり、テキストを理解する「テキストエンコーダー」と、それを基に画像を生成する「画像ジェネレーター」に大まかに分けられます。

さらに、画像ジェネレーターは「画像情報クリエイター」と、「画像デコーダー」の2つに分けられるとのこと。

主要なコンポーネントは、入力テキストを768次元のトークン埋め込みベクトル77個に出力する「テキストエンコーダー(ClipText)」、入力されたトークン埋め込みベクトルとノイズを処理された画像情報テンソルに出力する「画像情報クリエイター(UNet+Scheduler)」、入力された画像情報テンソルを色・幅・高さからなる画像に出力する「オートエンコーダー・デコーダー」からなります。

◆拡散モデル
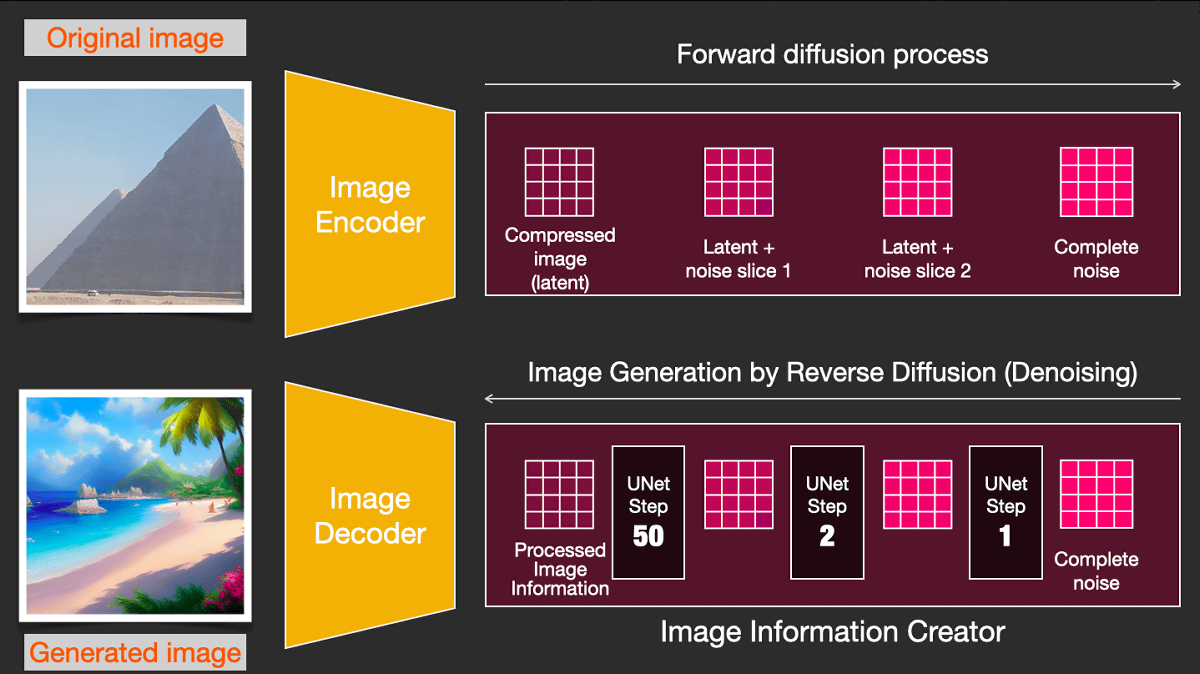
Stable DiffusionのDiffusion(拡散)とは、「画像情報クリエーター」の内部で行われるプロセスです。拡散モデルでは、「画像にノイズを繰り返し追加してノイズだけの画像を生成し、特定の時点で『前のステップでどれだけのノイズが追加されたのか』を予測する」という問題について考えます。
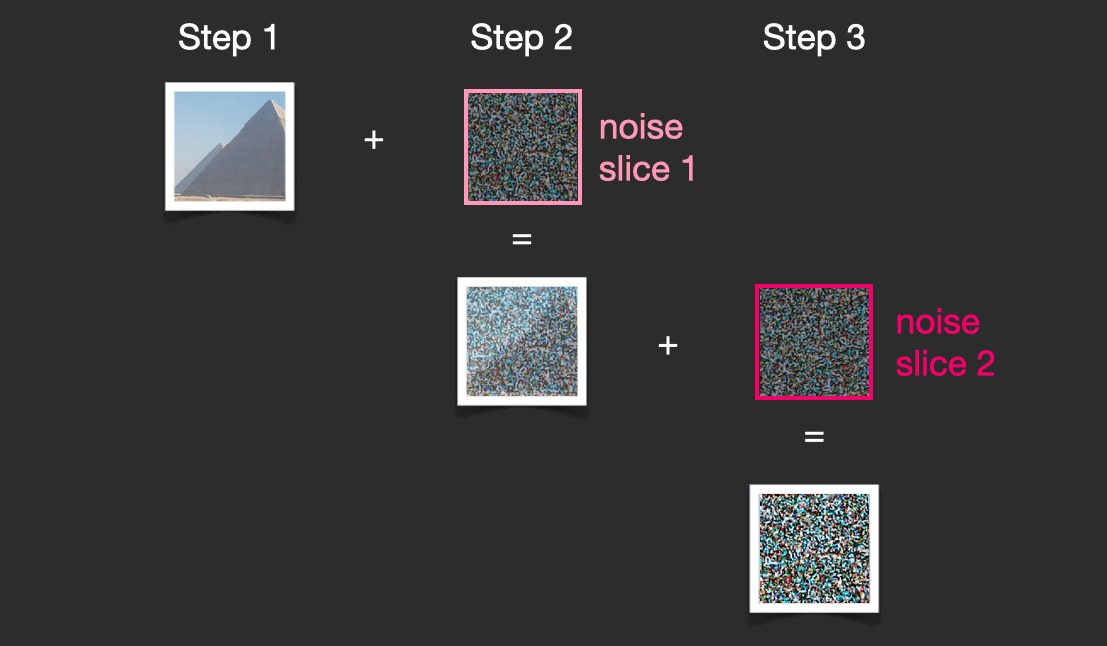
拡散モデルのトレーニングでは、画像に追加するノイズの量を調整することで、データセット内にあるすべての画像に対し数十ものトレーニングサンプルを生成できます。これが「拡散」と呼ばれるプロセスです。
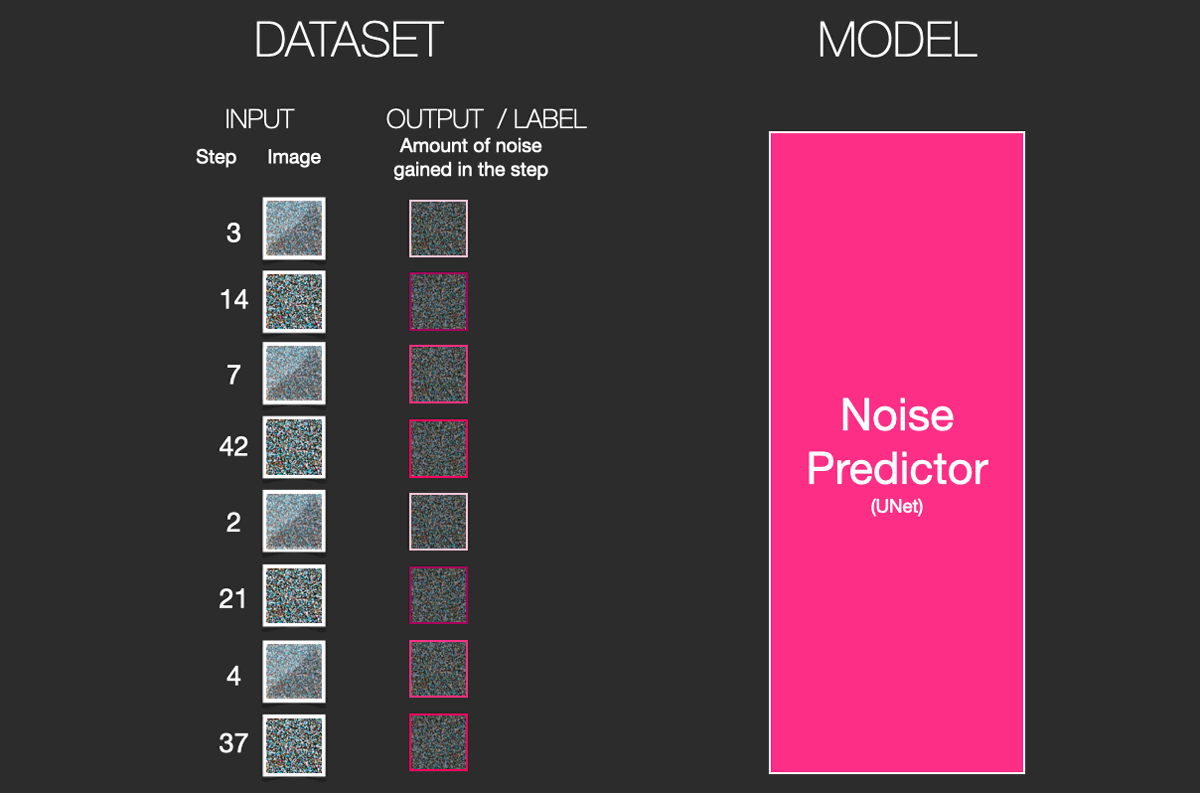
十分なトレーニングサンプルで訓練された拡散モデルは、拡散プロセスを逆方向に進めることが可能です。つまり、前のステップで画像に追加されたノイズを繰り返し予測・除去していくことにより、最終的にはきれいな画像を得られるようになるとのこと。

Stable Diffusionでは画像生成プロセスを高速化するため、実際のピクセル空間ではなくより低い次元の潜在空間を利用しています。オートエンコーダーが画像を潜在空間に圧縮し、潜在空間の情報にノイズを適用しているというわけです。
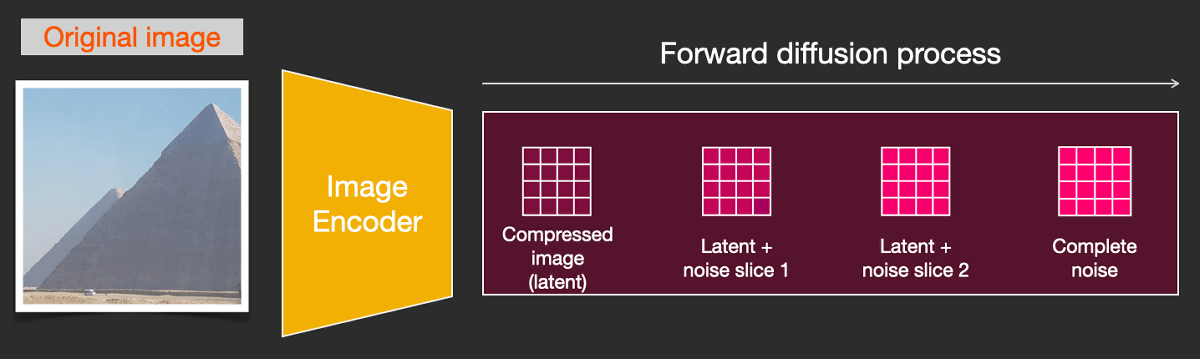
この場合でも拡散プロセスを逆方向に進め、きれいな画像の潜在空間バージョンを生成することが可能。最終的には画像デコーダーを介し、潜在空間の情報からピクセル空間の画像を生成しています。
◆テキストエンコーダー
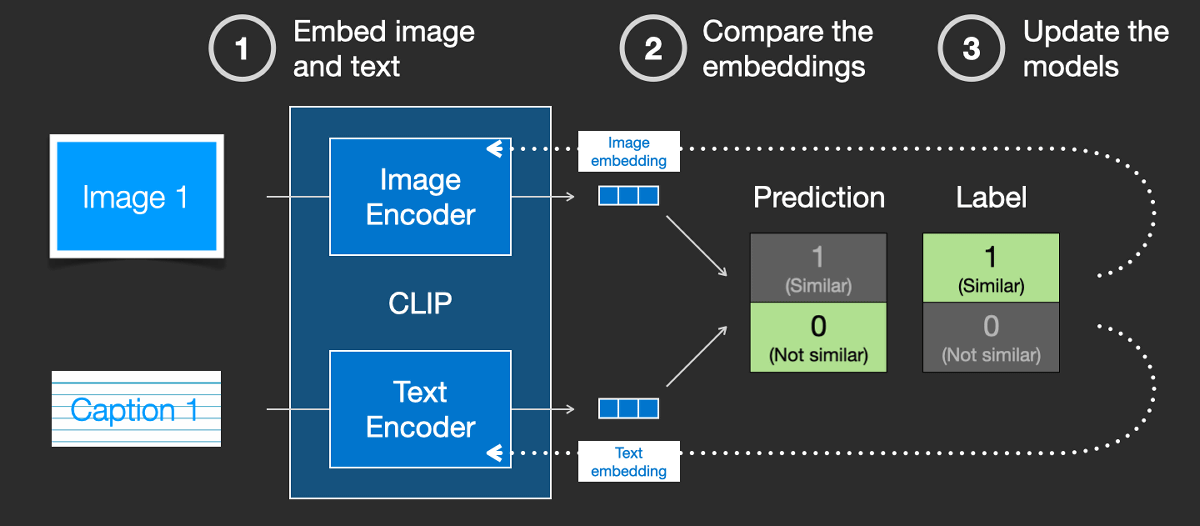
Stable Diffusionは単に画像を生成するだけではなく、入力されたテキストに基づいた画像を生成するため、潜在空間を利用した拡散モデルだけでは不十分です。記事作成時点のStable Diffusionは、OpenAIがリリースしたCLIPという事前トレーニング済みモデルを利用しています。CLIPは「画像」と「キャプション」の組み合わせからなるデータセットでトレーニングされています。

CLIPは画像エンコーダーとテキストエンコーダーの組み合わせであり、トレーニングデータを学習して結果を比較し、モデルに反映して精度を向上させています。これをデータセット全体で繰り返すことにより、「dog(犬)」というテキストを犬の画像と結びつけられるようになるとのこと。
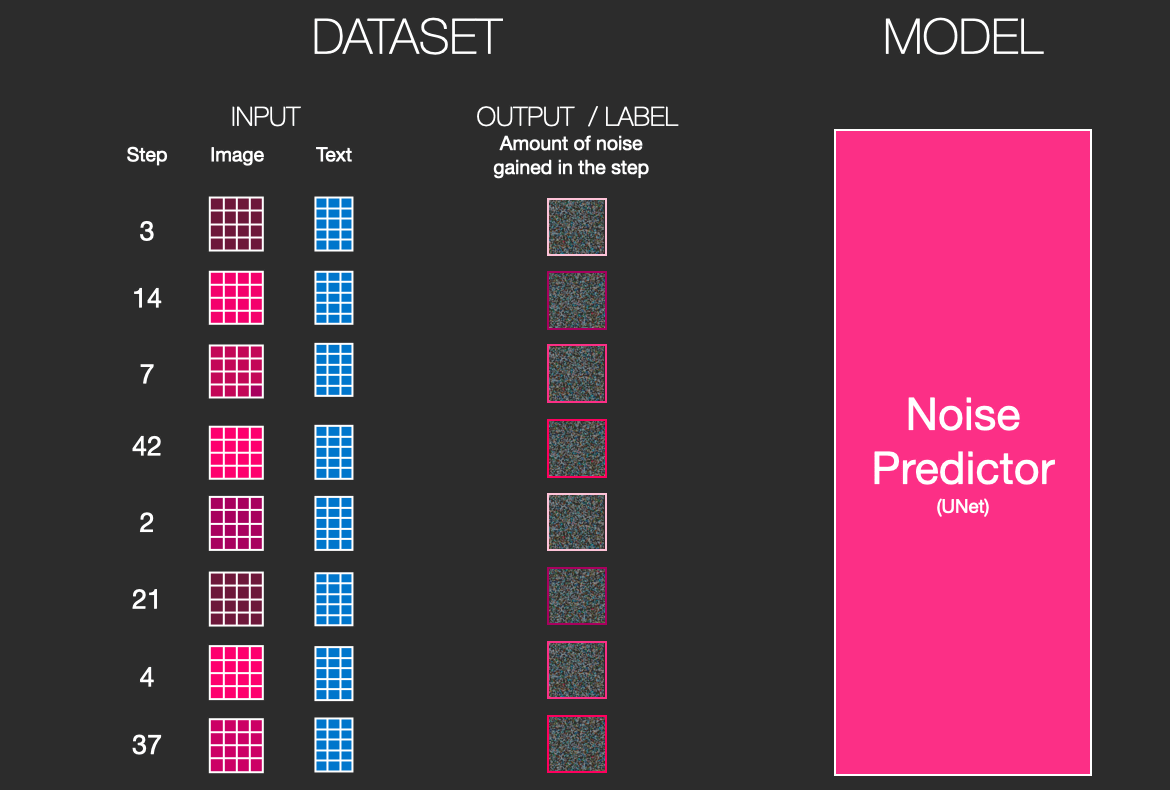
拡散モデルの画像生成プロセスにテキストデータを組み合わせるため、Stable Diffusionは潜在空間にエンコードされたテキストをノイズと共に入力してトレーニングされています。こうすることで、ノイズ除去の際にテキストデータを考慮し、テキストに沿った画像を生成できるというわけです。
◆Stable Diffusionの画像生成
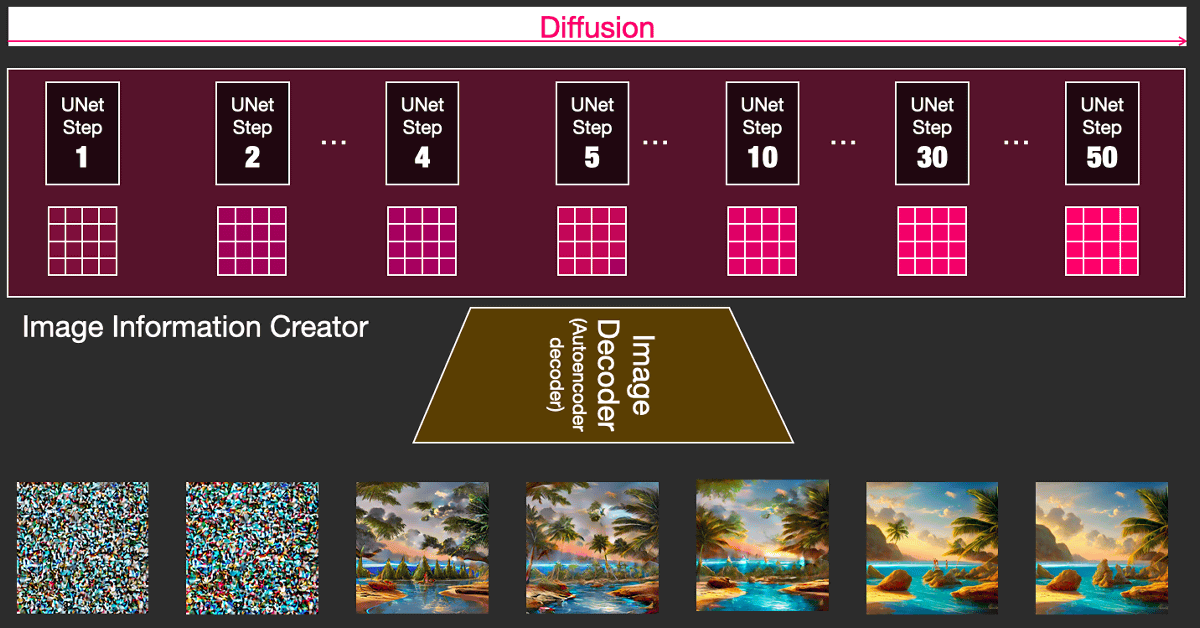
Stable Diffusionにおける画像生成を表した図がこれ。

潜在空間で処理される各ステップを、仮にいちいちデコーダーで画像として出力するとこんな感じ。ステップ2とステップ4の間でいきなり画像がそれらしくなっているのがわかります。
・関連記事
画像生成AI「Stable Diffusion」を4GBのGPUでも動作OK&自分の絵柄を学習させるなどいろいろな機能を簡単にGoogle ColaboやWindowsで動かせる決定版「Stable Diffusion web UI(AUTOMATIC1111版)」インストール方法まとめ - GIGAZINE
画像生成AI「Stable Diffusion web UI(AUTOMATIC1111版)」で元画像と似た構図や色彩の画像を自動生成したり指定した一部だけ変更できる「img2img」の簡単な使い方まとめ - GIGAZINE
画像生成AI「Stable Diffusion」を使いこなすために知っておくと理解が進む「どうやって絵を描いているのか」をわかりやすく図解 - GIGAZINE
アーティストの権利侵害やポルノ生成などの問題も浮上する画像生成AI「Stable Diffusion」の仕組みとは? - GIGAZINE
「AIが生成したイラストの投稿禁止」をイラスト投稿サイトが次々に決定し始めている - GIGAZINE
まるで人間のアーティストが描いたような画像を生成するAIが「アーティストの権利を侵害している」と批判される - GIGAZINE
画像生成AI「Midjourney」の描いた絵が美術品評会で1位を取ってしまい人間のアーティストが激怒 - GIGAZINE
・関連コンテンツ